This is the story of solving a problem, making a dictionary book online.
The dictionary
Njattyela Sreedharan (ഞാറ്റ്യേല ശ്രീധരൻ) is an 85 year old person from Kannur, Kerala. Out of his interest for Dravidian languages, he spent 25 years in compiling a dictionary of four Dravidian languages - Malayalam, Kannada, Tamil, Telugu.
The dictionary was originaly handwritten in a book of four columns. This was later published as a book by Senior Citizens Forum. This news article tells a better story than me here :)
The story of Njatyela Sreedharan's effort became a documentary and it won the National Film Award for Best Educational/Motivational/Instructional Film (2020).
The documentary is really good and seeing it gave me a huge motivation to make this dictionary online.
Start
The easiest way to make this dictionary book online is to convert the soft copy to a format understandable by dictpress.
A dictionary is structured data, in this case here is how the ideal structure looks like for each entry:
- Malayalam word
- Malayalam definition
- Tamil word
- Tamil definition
- Kannada word
- Kannada definition
- Telugu word
- Telugu definition
Pretty simple structure.
The soft copy we have is PDF and the Adobe Pagemaker 7 files.
Here is how the book/PDF/Pagemaker file looks like visually:
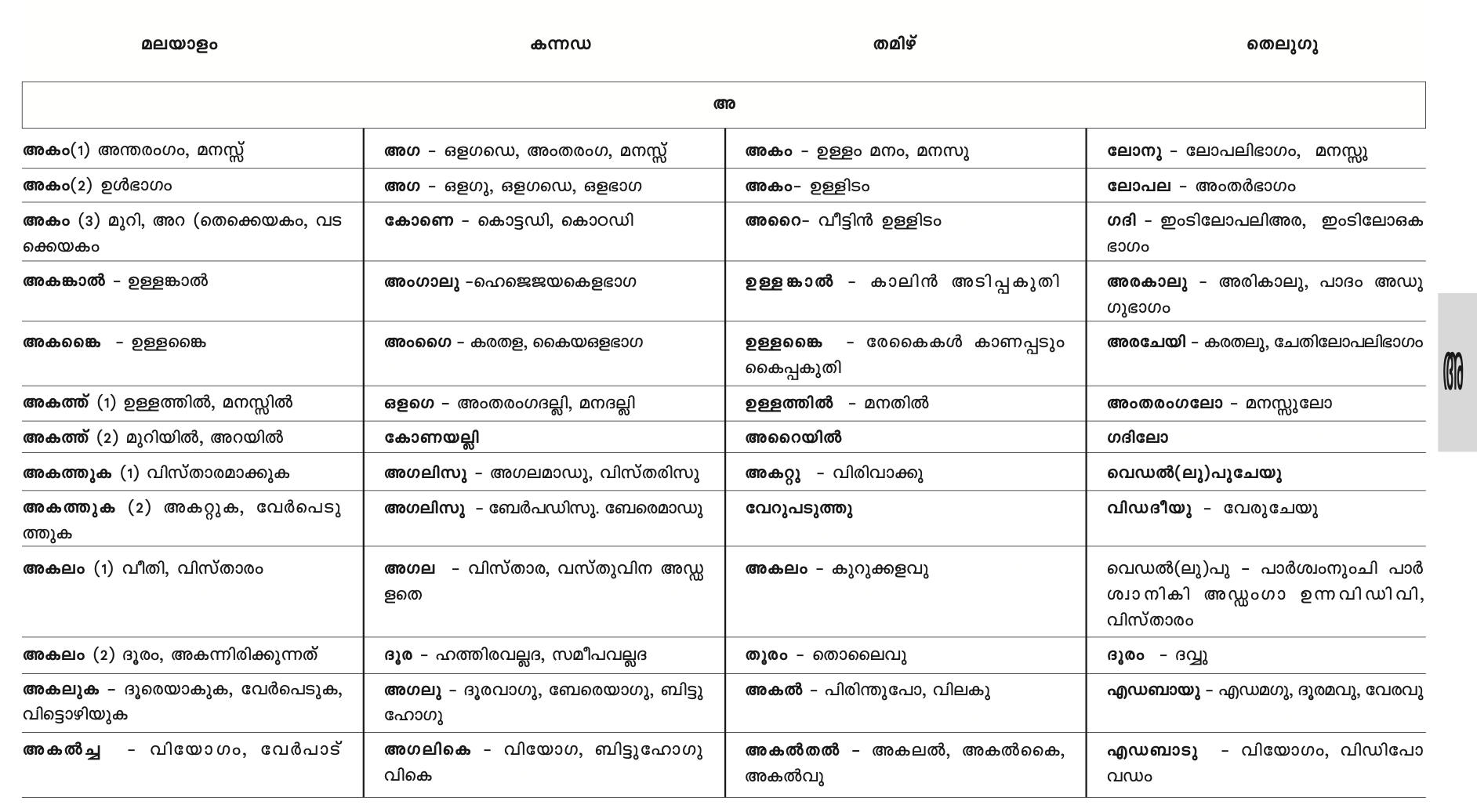
There are 4 columns. This looks all pretty in the front but behind the scenes the way it is created is superbly difficult to parse.
There are 4 hidden problems here to summarize:
- The Malayalam text is written in ASCII (Adobe Pagemaker 7 doesn't support Unicode)
- The way the table is created is not the best way to create a table, the black border is fake, it's an image
- There are hidden text in each cells to make the row alignment correct. These text has white text color, so it's not visible when printed, but when we try to copy text, we get these unwanted characters.
- In some pages, the ordering of columns is incorrect although it's shown correctly in PDF
Getting semantic data
HTML/XML is a good data structure for semantic data. HTML/XML is semantic in nature by default. Take this code for example
<tr>
<td><b>Apple</b></td>
<td>-</td>
<td>a fruit</td>
</tr>
The word and its meaning can be separated out from the above HTML very easily because the distinct content has its own tags. Since our PDF already shows text formatting like this, getting the HTML of it would help things out.
Attempt 1 - Extract from PDF
I used many tools to convert PDF to text/HTML but the output had no proper structure.
I learnt it the hard way that PDF is black magic, what you see is not what you get, copying the text from it is not giving the correct datapoints. Akshay gave an eye opener on this:
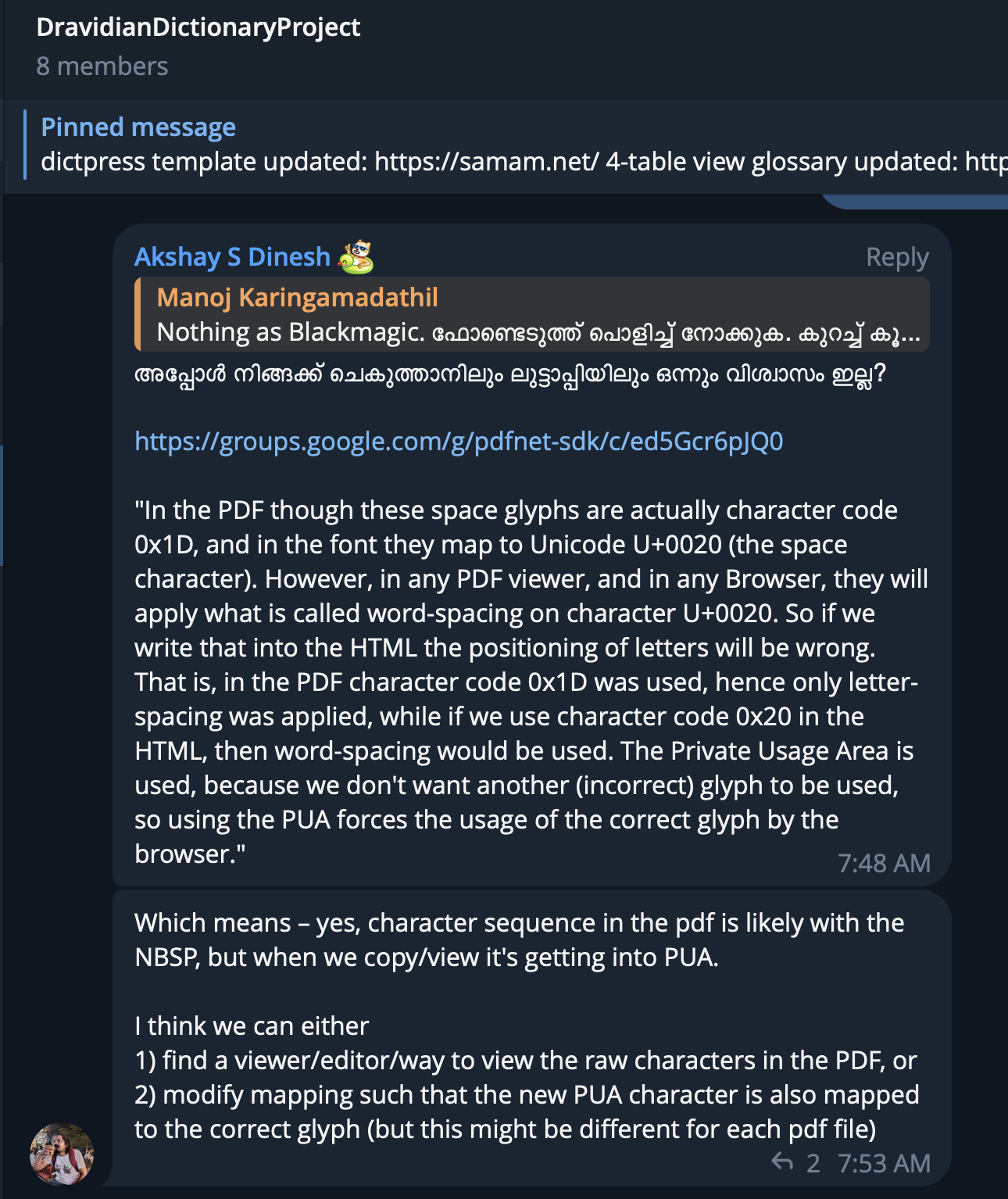
The first team call on how to make this into an online dictionary we learnt about all these problems, and things were looking bleak. The initial talks were all focused on the PDF and it was Joice who suggested if there's a possibility of getting HTML because it'd make things a lot easier.
Ok, so how do we get the HTML?
Attempt 2 - Extract from Pagemaker
Along with the PDF, we had the original .psd files.
Adobe officially stopped Pagemaker in 2004. It has a proprietary data format that is difficult to parse. Document Foundation (Libreoffice) has made a library libpagemaker to parse Pagemaker documents. (Side note: freaknz has made changes in libpagemaker to accomodate some rare Malayalam ASCII bugs)
But I wanted to see what this Pagemaker actually looked like. So I got a Windows machine that had Pagemaker.exe.
I opened these files in Pagemaker and could see an Export to HTML option. But as soon as I clicked the export button, Pagemaker crashed. I figured out that I have to not change any options in export and to be very careful in moving the mouse and clicking the "Export" button. Some weird bug.
Gotta appreciate the backward compatibility of Windows,
this 20+ year old software works smooth on a Windows 10 machine.
It is a good thing and also a bad thing.
I got the HTML output and it was not what I expected:

We have new problems now:
- The table data structure is weird, it is column wise instead of row wise
- There are empty cells in all kinda places
- Some entries continue into the next page
- Some entries doesn't have any Kannada Tamil Telugu values because it is a duplicate of some other entry
- Many more edge cases that I forgot (it's been 6 months since I last touched the code)
If I explained the solution of these, this blog post would go soooooooooo long. Here is the code which fixed these problems and made it into a CSV format:
Interesting tidbits
"Jack of all trades, master of none" is a quote that I often see from developers. For solving problems, these surface level knowledge of many things is actually very useful. You will know what to apply, where to apply.
I'm just gonna mention these trades.
Usage of jQuery
The best way to parse HTML is JavaScript (duh) and a swiss-knife that makes this easier is jQuery. I've used jQuery for various kind of things from building apps to browser automation.
Remember the problem of white color text in the PDF/HTML? This can be solved by removing all such white colored text like this:
$("font[color='#ffffff']").remove();
Pretty simple eh!
Usage of PHP
There are 10 HTML files, I want to first experiment with some tables, and then expand it to others. How do I dynamically load the HTML pages? The easiest way to do this is in PHP.
PHP is another swiss-knife for hacks. PHP's beginning itself is from quick shortcut hacks for making websites.
<?php
$number_of_tables = 100; // Configure how many tables to show
$src = file_get_contents("source-of-truth.html");
$table_count = 0;
$tables = preg_split('/\<\/table\>+/', $src);
for ($i = 0; $i < $number_of_tables; $i++) {
echo $tables[$i];
}
echo "</table>"
?>
<script src="fix-tables.js"></script>
<script src="make-csv.js"></script>
Unlike 2012, you don't need apache server for rendering PHP pages, you can do this
php -S localhost:3000
PHP + jQuery helped to get a CSV file but it was still in ASCII text
Usage of C++
payyans is a python library made in 2008 by Santhosh Thottingal for converting ASCII text to Unicode.
AlphaFork has made a desktop app called freaknz using the payyans logic. They made it for Janayugom newspaper's migration to Free/Libre software.
Freaknz desktop app is a very simple application that does the job really well. I simply copy pasted the CSV into it and got the Unicode output back.
payyans is in Python, freaknz is in C++, the logic of both is the same. There is also chathans reimplementing the same logic in C. To prevent this in future and to bring a standardization, we (SMC) have started a Go port of payyans. Just like Varnam, the output will be a C shared library which can be binded to in any other language.
Usage of Python
The next process was to convert the CSV into a format understandable by dictpress and along with it try to transliterate the Kannada, Tamil, Telugu text written in Malayalam script to its corresponding scripts.
libindic's transliteration module was used for this. It gave transliteration to native script, Latin script and IPA.
Usage of Go
dictpress is written in Go. It was created considering two languages like Olam which has English -> Malayalam and Malayalam -> Malayalam.
Accomodating samam, a 4 language dictionary into it is a task. Some new things had to be implemented for it. I consider this very hacky, and it is not following the relational DB way of handling things. It's just one JSONB column 😬. But hey it works.
Usage of Ruby on Rails
dictpress only gave a search -> result interface. The glossary view of dictpress lacks the ability to show a tabular structure like what the book/PDF had. That is the main hero here, the tabular view for comparitive study.
Modifying dictpress for this is a heavy task, glossary logic needs a change, new search logic needs to be implemented in glossary.
The easiest, fastest way to do this is to make it in Ruby on Rails. I was able to make the glossary view /glossary in 4 hours.
Side note: I haven't mentioned this in my blog, but for the past 2.5 years I've been working on Ruby on Rails and I love it. ActiveRecord and the rails console helped to do analysis, manipulations on the data easily:
Entry.find_each do |entry|
entry.update!(meta: JSON.parse(entry.notes))
rescue
print("error #{entry.id}")
end
ActiveRecord's elegance in handling DB data is another fantastic tool to do quick hacks. Both dictpress and the glossary app uses the same DB just to make it clear.
This is how the Entry model looks like:
class Entry < ApplicationRecord
LANGS = %i[malayalam kannada tamil telugu]
has_many :relations, foreign_key: :from_id
has_many :definitions, through: :relations, source: :to_entry
enum lang: Hash[LANGS.map { |symbol| [symbol, symbol.to_s] }]
LANGS.each do |target_lang|
define_method :"#{target_lang}_defintions" do
return self if lang.to_sym == target_lang
definitions.where(lang: target_lang).select(%i[content]).first
end
end
end
With the Ruby magic, this brings the convenience to do this:
first_entry = Entry.first
first_entry.malayalam_definitions
first_entry.tamil_definitions
Deployment
Akshay helped in setting up the server. In the era of Docker, Kubernetes blah blah blah deployment has gotten quite a complicated topic. We had a phone call on this and decided to keep it dumb simple:
Debian & ssh
Whatever deployment process you choose, what matters is the documentation and simplicity. Here is the doc we made.
Volunteer driven projects really need the simplicity.
And finally we have samam.net.
PS: I don't work in samam anymore.